Hiệu suất truy vấn là đề tài cực kỳ thú vị nhưng cũng rất thách thức khi làm việc với các câu lệnh T-SQL. Một câu truy vấn có hiệu suất cao đồng nghĩa với việc kết quả trả về cực nhanh, thời gian chờ của user ngắn sẽ mang lại trải nghiệm người dùng tốt hơn. Vậy làm thế nào chúng ta đánh giá hiệu suất của một câu truy vấn? Hiệu suất như thế nào là tốt và như thế nào là chưa tốt? Nếu có hai câu truy vấn cần so sánh nhau (như ở bài trước) làm sao xác định câu truy vấn nào hiệu quả hơn. Bài viết này sẽ chia sẻ cách đo lường hiệu suất truy vấn thông qua ba thông số phổ biến là CPU time, elapsed time và logical reads. Ý nghĩa của từng loại thông số sẽ được giải thích ở phần dưới bài viết, hiểu rõ những giá trị này tức là hiểu được mức độ đánh đổi tài nguyên để thực thi một câu truy vấn và điều này sẽ giúp kĩ thuật phân tích ,đánh giá của bạn chính xác hơn khi tối ưu hiệu suất truy vấn (query performance tuning).
Đo hiệu suất truy vấn trên session của mình
SQL Server cung cấp 2 câu lệnh SET STATISTICS TIME và SET STATISTICS IO để xuất ra thời gian và tài nguyên mà câu truy vấn đã dùng khi thực thi. STATISTICS TIME sẽ thống kê thông tin về cpu time và elapsed time, còn STATISTICS IO sẽ thống kê các thao tác về nhập xuất (I/O) liên quan. Đây là hai câu lệnh riêng biệt nên các bạn có thể chạy riêng lẻ và chúng chỉ ảnh hưởng đến mỗi session bạn đang chạy. Mình sẽ chạy cùng lúc cả hai câu lệnh trong cùng một demo vì đó chỉ thói quen của mình, hãy cùng xét câu truy vấn với điều kiện tìm kiếm ở mệnh đề HAVING
SET STATISTICS IO ON
SET STATISTICS TIME ON
--- điều kiện tìm kiếm ở mệnh đề HAVING
SELECT location, COUNT(*) AS cnt
FROM Users u
INNER JOIN Posts p ON u.Id = p.OwnerUserId
WHERE PostTypeId = 2
GROUP BY location
HAVING location LIKE '%vietnam%'
AND COUNT(*) > 10
ORDER BY cnt
OPTION(MAXDOP 1)
SET STATISTICS TIME OFF
SET STATISTICS IO OFF
Trong câu lệnh SELECT trên mình có thêm mệnh đề OPTION (MAXDOP 1) để đảm bảo SQL Server không sử dụng truy vấn song song (parallelism) mà là tuần tự (serial). Các bạn để ý cú pháp mình sử dụng ở đầu và cuối câu truy vấn là để bật và tắt tương ứng tính năng thống kê này, đây cũng là thói quen tốt trong lập trình nhằm kiểm soát mọi hành vi thừa thãi không cần thiết.
Kết quả thống kê nằm bên tab Messages và có định dạng như sau.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 3, logical reads 192, physical reads 9, read-ahead reads 183, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 7405, physical reads 3, read-ahead reads 7374, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 1, logical reads 800856, physical reads 4, read-ahead reads 800161, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 7969 ms, elapsed time = 18034 ms.
Đối với kết quả của SET STATISTICS TIME chúng ta có hai giá trị:
- CPU time: thời gian CPU đã sử dụng để cho ra kết quả dữ liệu, đơn vi là millisecond
- elapsed time: thời gian tính từ lúc SQL Server nhận được câu truy vấn cho đến khi trả xong dòng dữ liệu cuối cùng cho client.
Mình muốn bàn thêm một xíu về sự khác nhau và mối liên hệ giữa hai giá trị trên. Tổng thời gian thực thi một câu truy vấn duration (chính là giá trị elapsed time) bằng thời gian câu truy vấn đó sử dụng CPU cộng với thời gian chờ tài nguyên được cấp phát. Có thể hình dung ý trên bằng biểu thức sau:
elapsed time (duration) = CPU Time + Wait time
Wait time là tổng thời gian chờ nói chung cho tất cả các tài nguyên như chờ data được load lên buffer cache, chờ đặt khóa trên một resource nào đó, chờ cấp phát memory, chờ network,… chúng ta sẽ quay lại biểu thức này khi đến bài viết về wait and queue trong SQL Server .
Đối với kết quả của SET STATISTICS IO:
- Worktable/Workfile: Là những đối tượng tạm thời mà SQL Server đã tạo ra và sử dụng trong quá trình xử lý câu truy vấn. Bên cạnh việc truy xuất data của những bảng dữ liệu SQL Server cần dùng tới những đối tượng này để lưu trữ data tạm thời hoặc là do cơ chế hoạt động của một số thao tác (ví dụ như Hash Match, cái này thuộc phần execution plan sẽ đề cập ở bài viết khác) cần dùng tới.
- Table ‘Users’ và Table ‘Posts’: những bảng tham gia vào câu query đều xuất hiện trong kết quả thống kê.
- Logical reads: Số lượng data pages (8KB page) được đọc từ bộ nhớ (buffer cache) để lấy các dòng dữ liệu cần thiết. Đây là giá trị chúng ta cần quan tâm vì số lượng pages càng lớn câu truy vấn của bạn càng dùng nhiều CPU hơn và thời gian dài hơn. Để dễ hình dung có thể liên tưởng giá trị này là số lượng công việc phải làm.
- Physical reads: số lượng data pages (8KB page) được đọc lên từ disk để phục vụ câu truy vấn. Khi xử lý câu truy vấn, nếu page cần đọc đã ở trên buffer cache thì giá trị logical read sẽ được count, nếu chưa có thì storage engine sẽ gửi request I/O để đọc page đó từ disk và physical read đươc count, sau đó đến logical read được count.
- Scan count: số lần đọc thêm (có thể là seek hoặc scan) để đảm bảo ko bỏ sót dòng dữ liệu nào từ các page liền kề. Thông số này hơi khó hình dung nhưng một khi bạn hiểu rõ cấu tạo index trong SQL Server và cách index được truy cập sẽ mường tượng ra cách nó đếm giá trị này.
- Read-ahead read: số lượng data pages được đọc lên từ disk theo kiểu dự đoán. Nhằm tối ưu hiệu suất đọc data từ disk SQL Server có cơ chế dự đoán các pages sắp cần dùng để tự thực hiện các I/O request hiệu quả hơn thay vì chờ request page nào đọc page nấy. Các bạn có thể xem thêm thông tin liên quan ở đây.
Ngoài ra còn có các thống kê về LOB data với các thông số tương tự như 8KB pages. LOB data ám chỉ những data được khai báo với kiểu dữ liệu text, ntext, image, varchar(max), nvarchar(max) and varbinary(max) (gọi là large objects). Hai bảng chúng ta tham chiếu trong câu truy vấn không có các data type này nên giá trị chúng đều bằng 0.
Như mình nói ở đầu bài chúng ta chỉ cần chú ý tập trung ba giá trị CPU time, elapsed time và logical reads vì chúng là các thông số đầy đủ để đo lường hiệu suất của một câu truy vấn. Chúng ta thấy SQL Server mất 18,034 ms để thực hiện xong câu truy vấn trên, và thời gian sử dụng CPU là 7,969 ms. Theo như biểu thức mình chia sẻ thì thời gian chờ resources mất khoảng 10,065 ms. Câu truy vấn đã duyệt 7,405 pages của bảng Users và 800,856 pages của bảng Posts để lấy các dòng dữ liệu ra xử lý. Muốn thực hiện tối ưu truy vấn để chạy nhanh hơn chúng ta cần giảm thời gian chờ xuống mức tối thiểu ( thời gian chờ bằng không là tốt nhất), còn nếu muốn giảm CPU chúng ta cần tìm cách giảm logical reads từ hai bảng trên. Hiện tại chúng ta đang tìm cách đo đạt chi phí câu truy vấn và chúng ta cũng chưa đủ kiến thức, kĩ thuật, cũng như công cụ hỗ trợ cho việc tối ưu truy vấn nên chúng ta chỉ dừng lại ở mức phân tích và nhận xét như vậy.
Giờ chúng ta thử so sánh hai câu lệnh SELECT để xem câu nào chạy nhanh hơn. Theo bạn câu truy vấn có điều kiện tìm kiếm ở mệnh đề WHERE hay câu truy vấn có điều kiện tìm kiếm ở mệnh đề HAVING? Hãy nhấn F5 và xem kết quả nào. Các bạn lưu ý để đảm bảo data sẵn sàng trên buffer cache hãy chạy đoạn code sau 3 lần.
SET STATISTICS IO, TIME ON
--- điều kiện tìm kiếm ở mệnh đề HAVING
SELECT location, COUNT(*) AS cnt
FROM Users u
INNER JOIN Posts p ON u.Id = p.OwnerUserId
WHERE PostTypeId = 2
GROUP BY location
HAVING location LIKE '%vietnam%'
AND COUNT(*) > 10
ORDER BY cnt
OPTION (MAXDOP 1)
--- điều kiện tìm kiếm ở mệnh đề WHERE
SELECT location, COUNT(*) AS cnt
FROM Users u
INNER JOIN Posts p ON u.Id = p.OwnerUserId
WHERE PostTypeId = 2 AND location LIKE '%vietnam%'
GROUP BY location
HAVING COUNT(*) > 10
ORDER BY cnt
OPTION (MAXDOP 1)
SET STATISTICS IO, TIME OFF
Kết quả trả về trên máy của mình như sau:
(8 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 3, logical reads 192, physical reads 9, read-ahead reads 183, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 7405, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 1, logical reads 800856, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3750 ms, elapsed time = 3744 ms.
(8 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 1, logical reads 800856, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 7405, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2922 ms, elapsed time = 2940 ms.
Các bạn có thể đảo thứ tự của hai câu truy vấn để thêm khẳng định kết quả không ảnh hưởng bởi thứ tự. – Đầu tiên chúng ta thấy elapsed time của cả hai câu truy vấn đều xấp xỉ với CPU time của chúng, có nghĩa rằng toàn bộ thời gian truy vấn chính là thời gian dùng CPU, không có lãng phí một tí thời gian chờ resource nào cả, đây là dấu hiệu tốt cho cả hai câu truy vấn. – Thứ hai, lượng logical reads ở hai bảng dữ liệu chính là Users và Posts của cả hai câu truy vấn đều bằng nhau, chỉ có khác biệt ở bảng ‘workfile’ trên câu truy vấn có điều kiện tìm kiếm ở mệnh đề HAVING. Khác biệt là ở chỗ này, cách xử lý câu truy vấn bên trên phát sinh nhu cầu lưu trữ dữ liệu vào đối tượng ‘workfile’ trong khi câu bên dưới không cần. Ở bài sau khi tìm hiểu về execution plan mình sẽ chỉ cho các bạn thấy tại sao. – Thứ ba, xét giá trị CPU time thì câu lệnh SELECT có điều kiện tìm kiếm ở mệnh đề HAVING là 3,750 ms còn câu SELECT có điều kiện tìm kiếm ở mệnh đề WHERE là 2,922 ms. Câu dưới dùng ít tài nguyên CPU hơn và hoàn thành sớm hơn, nên hiệu năng truy vấn tốt hơn.
Như các bạn thấy chỉ cần dùng ba thông số CPU time, elapsed time, logical reads là có thể định lượng và so sánh hiệu suất của các câu truy vấn. Nhưng hai câu lệnh SET STATISTICS IO và TIME này chỉ ảnh hưởng trên session của ta, nếu muốn theo dõi hiệu suất truy vấn của một session nào khác thì làm thế nào? Tiếp theo chúng ta cùng điểm qua hai công cụ trên SQL Server để thực hiện yêu cầu này, đó là SQL Server Profiler và Extended Events, cả hai đều có chức năng thu thập các giá trị đo lường tương tự.
Cách đo hiệu suất truy vấn trên session người khác
Ở bài viết này mình không hướng dẫn cụ thể cách sử dụng SQL profiler cũng như extended event và mình nghĩ các bạn có thể dễ dàng tìm thấy hướng dẫn ở trên mạng. Để thấy được giá trị riêng của từng câu lệnh SELECT mình sẽ execute chúng từng lần một, và mình bắt sự kiện batch completed trên cả hai công cụ kết quả như hình bên dưới.
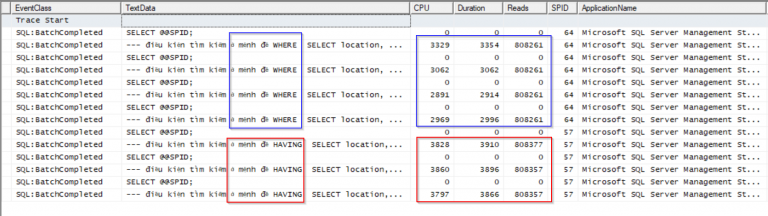
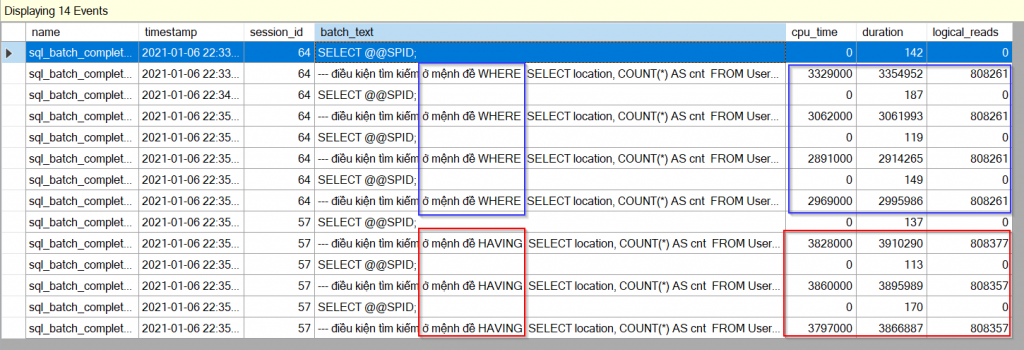
Trong cả hai hình trên các ô màu xanh là của câu lệnh có điều kiện tìm kiếm ở mệnh đề WHERE còn các ô màu đỏ là của câu lệnh có điều kiện tìm kiếm ở mệnh đề HAVING. Giá trị CPU time và duration (elapsed time) trên Extended Events có đơn vị là micro seconds. Những giá trị thu được từ hai công cụ này cũng phản ánh hiệu suất truy vấn đúng như những gì ta phân tích từ kết quả của hai câu lệnh SET STATISTICS ở trên.
Giữa hai cách trên mình khuyến khích sử dụng Extended Events, bởi vì sử dụng SQL Server Profiler sẽ tác động lớn đến hiệu năng của server đang chạy, đối với những servers có lượng request nhiều càng thấy rõ tầm ảnh hưởng của SQL Profiler đến %Processor Time (cao hơn bình thường rất nhiều). Trong khi đó Extended Events lại rất nhẹ nhàng, tốn chi phí rất thấp. Công cụ này được các chuyên gia về SQL Server sử dụng để troubleshooting các vấn đề về performance gặp phải trên môi trường production khi chúng ta muốn thu thập dữ liệu về hiệu năng từ session của người khác.
Đo hiệu suất những câu truy vấn đã từng chạy
Hầu hết các DBA đều sẽ nghe những phàn nàn kiểu như “hôm qua lúc 23:59 server chạy rất chậm” hoặc “câu query này hôm nay sao chạy chậm thế, mọi khi nó chạy nhanh lắm cơ mà”. Đó là khi chúng ta cần các thống kê hiệu suất truy vấn trong quá khứ để làm công tác tối ưu. Thật may là bản thân SQL Server có hỗ trợ chúng ta trong chuyện này. Mỗi khi SQL Server thực thi xong một câu truy vấn nó sẽ ghi lại một vài thông tin quan trọng liên quan đến hiệu năng nhằm giúp cho người quản trị có thể truy xuất và phân tích khi cần. Dynamic Management View (thường viết tắt là DMVs) là những view hệ thống mà SQL Server ghi lại trong quá trình làm việc nhằm giúp DBA dễ dàng hơn trong việc troubleshoot và có những tác động phù hợp, sys.dm_exec_query_stats sẽ là view chúng ta cần khảo sát.
Những thông tin trong này được lưu trữ dựa theo plan cache của các statements, có thể là những câu lệnh SELECT riêng lẻ (ad-hoc query) hoặc là các statements bên trong stored procedure. Chúng được lưu trữ trên bộ nhớ chính (memory) nên sẽ bị mất mỗi khi SQL Server restart, hoặc có thể mất khi server bị quá tải bộ nhớ (memory pressure) hoặc DBA chạy những câu lệnh xóa bộ nhớ (cache) chứa những thông số này và đặc biệt khi các statement bị recompile hoặc stored procedure bị alter. Một điều đáng chú ý đó là cách lưu trữ của view này là cộng dồn tất cả các lần chạy của câu lệnh đó. Hãy cùng xem ví dụ sau:
SELECT t.text, creation_time, last_execution_time, execution_count,
total_worker_time, total_elapsed_time, total_logical_reads,
(total_worker_time/execution_count)/1000 AS avg_cpu_time_ms,
(total_elapsed_time/execution_count)/1000 AS avg_elapsed_time_ms,
(total_logical_reads/execution_count) AS avg_logical_reads
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) t
WHERE t.text LIKE '%Posts%'
AND t.text NOT LIKE '%SELECT t.text%'

Trong câu truy vấn trên mình có join thêm với DMF (dynamic management function) sys.dm_exec_sql_text để lấy chính xác hai câu lệnh SELECT của chúng ta bằng cách filter những câu truy vấn có text chứa từ Posts. Kết quả trả về là nội dung hai câu truy vấn đó cùng với thông tin như tạo ra lúc nào, lần cuối thực thi là khi nào, tổng số lần thực thi cho tới hiện tại, tổng CPU time (worker time), tổng elapsed time, và tổng logical reads. Ba cột cuối trong result set là giá trị trung bình của các thông số bằng cách lấy tổng chia cho số lần execution, ngoài ra bản thân DMV này còn chứa rất nhiều thông tin khác các bạn có thể tự khám phá thêm.
Với cách lưu trữ như vậy chúng ta chỉ biết tương đối hiệu năng truy vấn của chúng trong những ngày trước nhưng cũng rất hữu ích để tham khảo khi troubleshoot những vấn đề về hiệu năng. Nếu các bạn muốn những giá trị này chính xác hơn hãy tạo một SQL Agent job để capture chúng theo thời gian, với từng khoảng thời gian nhỏ giá trị trung bình càng thể hiện chính xác những gì chúng đã thực thi.
Ở bài này mình đã chia sẻ với các bạn những thông số quan trọng thường được sử dụng để xác định hiệu năng của một câu truy vấn, mình đã giải thích ý nghĩa của từng thông số cũng như cách thu thập chúng. Cùng với những phân tích dựa trên kết quả của hai câu lệnh đếm sao để giúp các bạn dễ dàng làm quen và hiểu cách sử dụng những giá trị này. Hi vọng nó giúp ích phần nào cho các bạn khi làm việc với SQL Server, đặc biệt là tối ưu câu truy vấn T-SQL.
Nguồn tham khảo:
- worktable và workfile trong câu lệnh SET STATISTICS IO
- Microsoft document SET STATISTICS IO
- Microsoft document SET STATISTICS TIME
- Reading pages in SQL Server
Nguồn: quantricsdulieu