Các thông số hiệu suất chính của Apache Cassandra
Bằng cách theo dõi hiệu suất của Apache Cassandra, bạn có thể xác định sự chậm chạp, trục trặc hoặc các giới hạn tài nguyên đang gặp phải — và thực hiện hành động nhanh chóng để khắc phục chúng. Một số lĩnh vực chính mà bạn sẽ muốn nắm bắt và phân tích các thông số là:
- Thông lượng, đặc biệt là yêu cầu đọc và ghi
- Độ trễ, đặc biệt là độ trễ đọc và ghi
- Sử dụng ổ cứng, đặc biệt là dung lượng ổ cứng trên mỗi nút
- Tần suất và thời gian thu gom rác
- Lỗi và quá tải, đặc biệt là các ngoại lệ không có sẵn cho biết các yêu cầu không thành công do không có sẵn các nút trong cụm
Các thông số hiệu suất của Apache Cassandra có thể truy cập được bằng nhiều công cụ khác nhau, bao gồm tiện ích nodetool của Cassandra, ứng dụng JConsole và các công cụ giám sát tương thích với JMX hoặc Metrics.
Thông lượng
| Tên | Miêu tả | Loại thông số | Công cụ có sẵn |
|---|---|---|---|
| Reads | Số lượng yêu cầu đọc trên giây | Work: Throughput | JConsole, JMX/Metrics reporters |
| Writes | Số lượng yêu cầu ghi trên giây | Work: Throughput | JConsole, JMX/Metrics reporters |
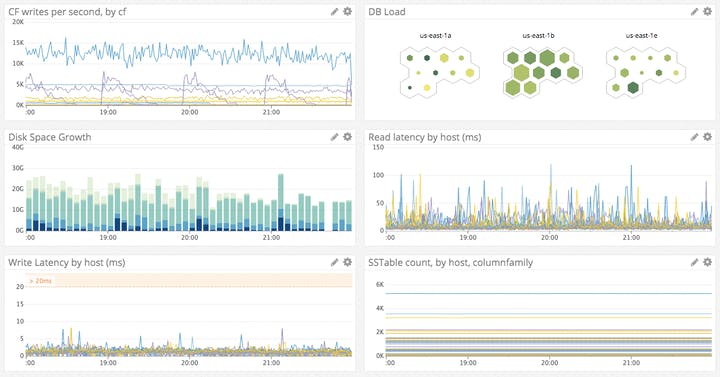
Việc giám sát các yêu cầu — cả đọc và ghi — mà Cassandra đang nhận vào bất kỳ thời điểm nào cung cấp cho bạn một cái nhìn cấp cao về mức độ hoạt động của cụm Cassandra. Hiểu cách thức — và mức độ — cụm của bạn đang được sử dụng sẽ giúp bạn tối ưu hóa hiệu suất của Cassandra. Ví dụ: chiến lược nén nào bạn chọn (xem phần sử dụng ổ cứng bên dưới) có thể sẽ phụ thuộc vào việc khối lượng công việc của bạn có xu hướng nặng về đọc hay ghi nhiều.
Các chỉ số tiêu chuẩn của Cassandra bao gồm các đường trung bình động có trọng số theo cấp số nhân cho các yêu cầu trong khoảng thời gian 15 phút, năm phút và một phút. Thông lượng đọc và ghi trong tần suất một phút đặc biệt hữu ích cho khả năng hiển thị gần như tức thời. Các chỉ số độ trễ này có sẵn từ Cassandra được tổng hợp theo loại yêu cầu (ví dụ: đọc hoặc ghi) hoặc theo họ cột (tương tự một bảng cơ sở dữ liệu của Cassandra).
Thông số cần cảnh báo: Thông lượng đọc
Theo dõi tỷ lệ truy vấn tại bất kỳ thời điểm nào cung cấp chế độ xem cấp cao nhất về cách người dùng của bạn đang tương tác với Cassandra. Và vì Cassandra vượt trội trong việc xử lý khối lượng ghi lớn, bạn thường sẽ muốn theo dõi chặt chẽ tốc độ đọc để tìm ra các vấn đề tiềm ẩn hoặc những thay đổi đáng kể trong các mẫu truy vấn của người dùng của bạn. Cân nhắc cảnh báo về mức tăng đột biến liên tục (trên đường cơ sở trước đây) hoặc sự sụt giảm đột ngột, bất ngờ (trên cơ sở phần trăm trong một khung thời gian ngắn) về thông lượng.
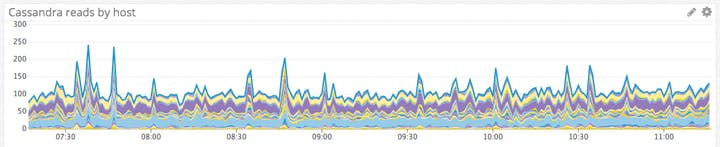
Thông số cần cảnh báo: Thông lượng ghi
Cassandra sẽ có thể xử lý số lượng lớn các bản ghi một cách nhuần nhuyễn. Tuy nhiên, rất đáng để theo dõi khối lượng yêu cầu ghi đến Cassandra để bạn có thể theo dõi mức độ hoạt động tổng thể của cụm và theo dõi bất kỳ mức tăng đột biến hoặc sụt giảm bất thường nào cần điều tra thêm.
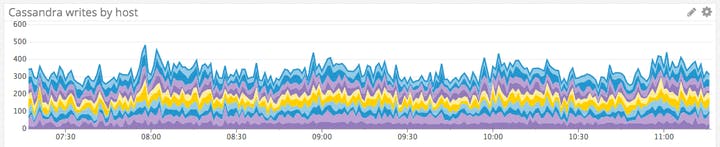
Độ trễ
| Tên | Miêu tả | Loại thông số | Công cụ có sẵn |
|---|---|---|---|
| Write latency | Thời gian phản hồi ghi, tính bằng micro giây | Work: Performance | nodetool, JConsole, JMX/Metrics reporters |
| Read latency | Thời gian phản hồi đọc, tính bằng micro giây | Work: Performance | nodetool, JConsole, JMX/Metrics reporters |
| Key cache hit rate | Một số yêu cầu đọc mà vị trí của khóa trên ổ cứng được tìm thấy trong bộ nhớ đệm | Other | nodetool, JConsole, JMX/Metrics reporters |
Giống như bất kỳ hệ thống cơ sở dữ liệu nào, Cassandra có những hạn chế của nó — ví dụ, không có liên kết nào trong Cassandra và việc truy vấn bằng bất kỳ thứ gì khác ngoài khóa hàng đòi hỏi nhiều bước. Ưu điểm là Cassandra thực hiện các cân bằng như thế này để đảm bảo ghi nhanh trên một kho dữ liệu lớn, phân tán.
Vì vậy, bất kể trường hợp sử dụng Cassandra của bạn, rất có thể bạn quan tâm rất nhiều đến hiệu suất ghi. Và đối với nhiều ứng dụng, chẳng hạn như hỗ trợ các truy vấn của người dùng, hiệu suất đọc cũng cực kỳ quan trọng. Theo dõi độ trễ cung cấp cho bạn một cái nhìn quan trọng về hiệu suất Cassandra tổng thể và có thể chỉ ra các vấn đề đang phát triển hoặc sự thay đổi trong cách sử dụng có thể yêu cầu điều chỉnh đối với cụm Cassandra của bạn.
Cassandra phân chia thống kê độ trễ thành một số số liệu khác nhau, nhưng có lẽ số liệu đơn giản nhất và có giá trị cao nhất để theo dõi là độ trễ đọc và ghi hiện tại. Chỉ số độ trễ ghi của Cassandra đo số micro giây cần thiết để thực hiện yêu cầu ghi, trong khi độ trễ đọc đo lường như nhau đối với các yêu cầu đọc. Việc hiểu cần tìm những gì trong các chỉ số này đòi hỏi một chút kiến thức cơ bản về cách Cassandra xử lý các yêu cầu.
Chỉ số cần cảnh báo: Độ trễ ghi
Cassandra ghi thường nhanh hơn nhiều so với đọc, vì một lần ghi chỉ cần được ghi lại trong bộ nhớ và được thêm vào một commit log lâu dài trước khi nó được thừa nhận là thành công. Các mức độ trễ cụ thể mà bạn cho là có thể chấp nhận được sẽ tùy thuộc vào trường hợp sử dụng của bạn. Việc ghi bị chậm kinh niên chỉ ra các vấn đề mang tính hệ thống; bạn có thể cần nâng cấp ổ cứng lên SSD để nhanh hơn hoặc kiểm tra cài đặt tính nhất quán của mình. (Cài đặt tính nhất quán ‘EACH_QUORUM’, ví dụ: cài đặt tính nhất quán yêu cầu giao tiếp giữa các data centers, cái mà có thể cách xa nhau về mặt địa lý). Nhưng một sự thay đổi đột ngột, như được thấy ở giữa biểu đồ chuỗi thời gian bên dưới, thường chỉ ra những phát triển tiềm ẩn có vấn đề như sự cố mạng hoặc thay đổi trong việc sử dụng các mẫu (ví dụ: sự gia tăng đáng kể kích thước của các phần thêm vào cơ sở dữ liệu).
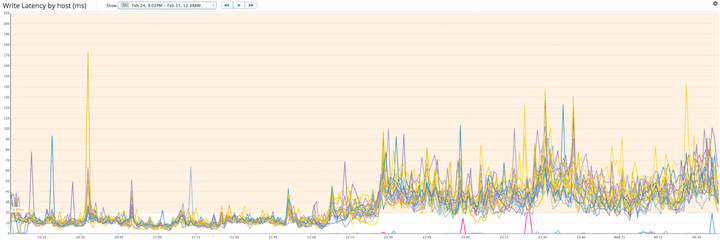
Chỉ số cần cảnh báo: Độ trễ đọc
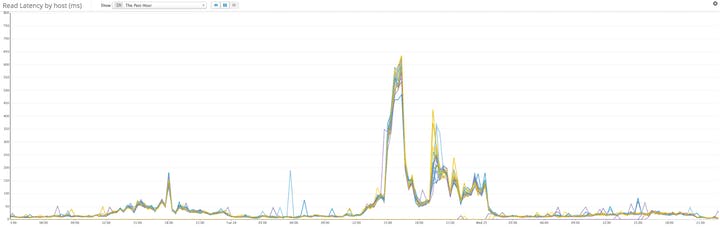
Các thao tác đọc của Cassandra thường chậm hơn nhiều so với thao tác ghi, vì quá trình đọc liên quan đến nhiều I/O hơn. Nếu một hàng được cập nhật thường xuyên, hàng đó có thể nằm rải rác trên một số SSTables, làm tăng độ trễ của việc đọc. Tuy nhiên, độ trễ đọc có thể là một số liệu rất quan trọng cần theo dõi, đặc biệt nếu các truy vấn Cassandra đang cung cấp dữ liệu vào một ứng dụng giao diện người dùng. Đọc chậm có thể chỉ ra các vấn đề với phần cứng hoặc mô hình dữ liệu của bạn hoặc một thông số khác cần được điều chỉnh, chẳng hạn như chiến lược nén. Đặc biệt, nếu độ trễ đọc bắt đầu tăng cao trong một cụm đang chạy nén theo cấp độ, đó có thể là dấu hiệu cho thấy các nút đang vật lộn để xử lý khối lượng ghi và các hoạt động nén liên quan.
Sử dụng ổ cứng
| Tên | Miêu tả | Loại thông số | Công cụ có sẵn |
|---|---|---|---|
| Load | Dung lượng đĩa được sử dụng trên một nút, tính bằng byte | Resource: Utilization | nodetool, JConsole, JMX/Metrics reporters |
| Total disk space used | Dung lượng đĩa được sử dụng bởi một họ cột, tính bằng byte | Resource: Utilization | nodetool, JConsole, JMX/Metrics reporters |
| Completed compaction tasks | Tổng số tác vụ nén đã hoàn thành | Resource: Other | JConsole, JMX/Metrics reporters |
| Pending compaction tasks | Tổng số tác vụ nén trong hàng đợi | Resource: Saturation | nodetool, JConsole, JMX/Metrics reporters |
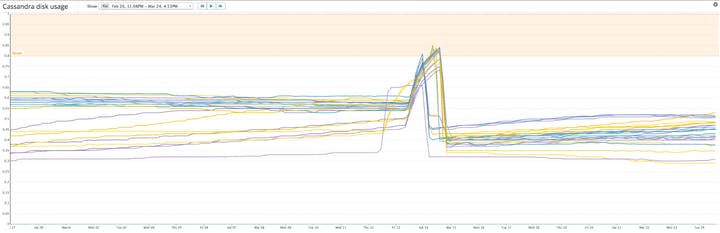
Bạn gần như chắc chắn sẽ muốn theo dõi lượng ổ đĩa mà Cassandra đang sử dụng trên mỗi nút trong cụm của bạn để bạn có thể thêm nhiều nút hơn trước khi hết bộ nhớ.
Cassandra tiết lộ một số số liệu ổ đĩa khác nhau, nhưng những số liệu đơn giản nhất để theo dõi là tải hoặc tổng dung lượng đĩa được sử dụng. Chỉ số “load (tải)” không liên quan gì đến việc xử lý tải hoặc yêu cầu trong hàng đợi; đúng hơn nó là một số liệu cấp độ nút cho biết số lượng ổ đĩa, tính bằng byte, được sử dụng bởi nút đó. Tổng dung lượng ổ đĩa đã sử dụng cung cấp tổng số byte được sử dụng bởi một họ cột nhất định (tương tự bảng cơ sở dữ liệu của Cassandra). Nếu bạn tổng hợp một trong hai chỉ số trên toàn bộ cụm của mình, bạn sẽ biết kích thước tổng thể của kho dữ liệu Cassandra của mình.
Dung lượng đĩa trống bạn cần để duy trì tùy thuộc vào chiến lược nén mà họ cột Cassandra của bạn sử dụng. Khi Cassandra ghi dữ liệu vào đĩa, nó sẽ làm như vậy bằng cách tạo một tệp không thay đổi được gọi là SSTable. Cập nhật dữ liệu được quản lý bằng cách tạo SSTables mới, có dấu thời gian; Việc xóa được thực hiện bằng cách đánh dấu dữ liệu cần xóa bằng “tombstones”. Để tối ưu hóa hiệu suất đọc và sử dụng đĩa, Cassandra định kỳ chạy nén để hợp nhất các SSTables và loại bỏ dữ liệu đã lỗi thời hoặc được lưu trữ.
Trong quá trình nén, Cassandra tạo và hoàn thành các SSTables mới trước khi xóa những cái cũ; điều này có nghĩa là SSTables cũ và mới tạm thời cùng tồn tại, làm tăng mức sử dụng đĩa ngắn hạn trên cụm. Kích thước của sự gia tăng đó (và do đó không gian đĩa cần thiết) thay đổi rất nhiều theo chiến lược nén:
- Chiến lược nén mặc định, nén theo cấp kích thước, hợp nhất các SSTables có kích thước tương tự. Tính năng nén theo cấp kích thước yêu cầu không gian đĩa có sẵn nhiều nhất (50% trở lên tổng dung lượng đĩa) vì trong trường hợp khắc nghiệt nhất, nó có thể tạm thời tăng gấp đôi lượng dữ liệu được lưu trữ trong Cassandra. Chiến lược này được thiết kế cho khối lượng công việc nặng về ghi dữ liệu.
- Các nhóm nén theo tầng cấp SSTables thành các cấp độ lớn hơn dần dần, trong đó mỗi SSTable không chồng chéo. Chiến lược này tập trung vào I/O hơn là nén theo cấp kích thước, nhưng nó đảm bảo rằng phần lớn thời gian đọc có thể được đáp ứng bởi một SSTable duy nhất, thay vì đọc từ các phiên bản khác nhau của một hàng trải rộng trên nhiều SSTable. Bên cạnh việc cung cấp các lợi ích về hiệu suất cho các mục đích sử dụng chuyên sâu, nén theo cấp độ cũng yêu cầu chi phí trên đĩa ít hơn nhiều (khoảng 10% đĩa) để sử dụng tạm thời trong quá trình nén.
- Nén theo tầng ngày, một tùy chọn mới hơn được tối ưu hóa cho dữ liệu theo chuỗi thời gian, nhóm và thu gọn SSTables dựa trên tuổi của các điểm dữ liệu mà chúng chứa. Nén theo tầng ngày có các cửa sổ nén có thể định cấu hình, do đó, không gian đĩa cần thiết cho quá trình nén có thể được kiểm soát bằng cách điều chỉnh các tùy chọn chẳng hạn như lệnh ‘maxSSTableAgeDays’ cho Cassandra ngừng nén SSTables sau khi chúng đạt đến một độ tuổi nhất định.
Hoạt động nén có thể được theo dõi thông qua các chỉ số cho completed compaction tasks và pending compaction tasks. Các giao dịch đã hoàn thành sẽ tự nhiên có xu hướng tăng lên với hoạt động ghi tăng lên, nhưng hàng đợi các tác vụ nén đang chờ xử lý ngày càng tăng cho thấy rằng cụm Cassandra không thể theo kịp khối lượng công việc, thường là do các hạn chế I/O hoặc tranh chấp tài nguyên có thể yêu cầu bổ sung thêm nút mới.
Chỉ số cần cảnh báo: Tải
Việc giám sát đĩa được sử dụng bởi mỗi nút có thể cảnh báo bạn về một cụm không cân bằng hoặc các hạn chế tài nguyên đang tồn tại. Tùy thuộc vào cách cụm Cassandra của bạn được sử dụng và chiến lược nén mà bạn chọn, bạn có thể theo dõi việc sử dụng đĩa để xác định khi nào bạn nên thêm nhiều nút hơn vào cụm của mình để đảm bảo rằng Cassandra luôn có đủ chỗ để chạy các giao dịch.
Thu gom rác
| Tên | Miêu tả | Loại thông số | Công cụ có sẵn |
|---|---|---|---|
| ParNew count | Số lượng rác mới | Other | nodetool,* JConsole, JMX/Metrics reporters |
| ParNew time | Thời gian đã trôi qua của các rác mới, tính bằng mili giây | Other | nodetool,* JConsole, JMX/Metrics reporters |
| ConcurrentMarkSweep count | Số lượng rác cũ | Other | nodetool,* JConsole, JMX/Metrics reporters |
| ConcurrentMarkSweep time | Thời gian đã trôi qua của các rác cũ, tính bằng mili giây | Other | nodetool,* JConsole, JMX/Metrics reporters |
Lưu ý số liệu báo cáo nodetool về tất cả các bộ gom rác, bất kể loại nào
Vì Cassandra là một hệ thống dựa trên Java, nó dựa vào các quy trình thu thập rác của Java để giải phóng bộ nhớ. Càng nhiều hoạt động trong cụm Cassandra của bạn, trình thu gom rác sẽ chạy càng thường xuyên. Hình thức thu gom rác phụ thuộc vào việc thu gom thế hệ mới (vật thể mới) hay thế hệ cũ (vật thể tồn tại lâu đời).
ParNew, hoặc thế hệ mới, việc thu gom rác diễn ra tương đối thường xuyên. ParNew là bộ sưu tập rác toàn thế giới, có nghĩa là tất cả các luồng ứng dụng tạm dừng trong khi tiến hành thu gom rác, vì vậy bất kỳ sự gia tăng đáng kể nào về độ trễ của ParNew sẽ ảnh hưởng đến hiệu suất của Cassandra.
Bộ sưu tập ConcurrentMarkSweep (CMS) giải phóng bộ nhớ không sử dụng trong thế hệ cũ của heap. CMS là một bộ sưu tập rác có mức tạm dừng thấp, có nghĩa là mặc dù nó tạm thời dừng các luồng ứng dụng, nhưng nó chỉ hoạt động không liên tục. Nếu CMS mất vài giây để hoàn thành hoặc đang xảy ra với tần suất tăng lên, cụm của bạn có thể không có đủ bộ nhớ để hoạt động hiệu quả.
Lỗi và quá tải
| Tên | Miêu tả | Loại thông số | Công cụ có sẵn |
|---|---|---|---|
| Exceptions | Các yêu cầu mà Cassandra gặp phải lỗi (thường là không nghiêm trọng) | Work: Error | nodetool, JConsole, JMX/Metrics reporters |
| Timeout exceptions | Yêu cầu không được xử lý nhận trong khoảng thời gian chờ có thể định cấu hình | Work: Error | JConsole, JMX/Metrics reporters |
| Unavailable exceptions | Yêu cầu không có số lượng nút bắt buộc | Work: Error | JConsole, JMX/Metrics reporters |
| Pending tasks | Các tác vụ trong hàng đợi một chuỗi xử lý | Resource: Saturation | nodetool, JConsole, JMX/Metrics reporters |
| Currently blocked tasks | Các tác vụ chưa thể xếp vào hàng đợi để xử lý | Resource: Saturation | nodetool, JConsole, JMX/Metrics reporters |
Nếu cụm của bạn không còn có thể xử lý luồng yêu cầu đến vì bất kỳ lý do gì, bạn cần biết ngay lập tức. Một cửa sổ dẫn đến các vấn đề tiềm ẩn là số lượng exceptions của Cassandra. Nói chung, bạn muốn con số này rất nhỏ, mặc dù không phải tất cả các trường hợp ngoại lệ đều được tạo ra như nhau.
Ví dụ, timeout exception của Cassandra’s phản ánh việc xử lý không đầy đủ (nhưng không thất bại) đối với một yêu cầu. Thời gian chờ xảy ra khi nút điều phối viên gửi yêu cầu đến bản sao và không nhận được phản hồi trong khoảng thời gian chờ có thể định cấu hình. Thời gian chờ không nhất thiết phải nghiêm trọng — điều phối viên sẽ lưu trữ bản cập nhật và cố gắng áp dụng nó sau — nhưng họ có thể chỉ ra các vấn đề về mạng hoặc thậm chí ổ đĩa sắp hết dung lượng. Cài đặt read_request_timeout_in_ms (mặc định là 5.000 ms), write_request_timeout_in_ms (mặc định là 2.000 ms) và các khoảng thời gian chờ khác có thể được đặt trong tệp cấu hình cassandra.yaml.
Một loại ngoại lệ đáng lo ngại hơn là ngoại lệ không có sẵn, điều này chỉ ra rằng Cassandra không thể đáp ứng các yêu cầu nhất quán cho một yêu cầu nhất định, thường là do một hoặc nhiều nút đã được báo cáo là không hoạt động khi yêu cầu đến. Ví dụ: trong một cụm có hệ số sao chép là ba và mức độ nhất quán là ALL, một yêu cầu đọc hoặc ghi sẽ cần phải đạt được tất cả ba nút sao chép trong cụm để thực hiện đọc hoặc ghi thành công.
Một cách khác để phát hiện các dấu hiệu của các vấn đề mới xảy ra là theo dõi trạng thái của các tác vụ của Cassandra khi nó xử lý các yêu cầu. Mỗi loại tác vụ trong Cassandra (ví dụ: tác vụ ReadStage) có một hàng đợi cho các tác vụ đến và được phân bổ một số luồng nhất định để thực hiện các tác vụ đó. Nếu tất cả các luồng đang được sử dụng, các tác vụ sẽ tích lũy trong hàng đợi chờ một luồng có sẵn. Số lượng tác vụ trong hàng đợi tại bất kỳ thời điểm nhất định nào được mô tả bằng số liệu pending tasks. Khi hàng đợi các tác vụ đang chờ xử lý đầy lên, Cassandra sẽ đăng ký các tác vụ sắp đến bổ sung như hiện bị chặn (currently blocked), mặc dù những tác vụ đó cuối cùng có thể được chấp nhận và thực hiện.
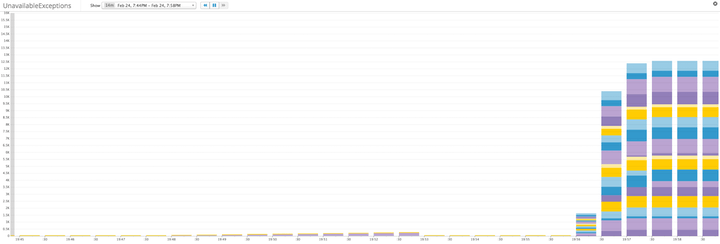
Chỉ số cần cảnh báo: Các ngoại lệ không có sẵn
Một ngoại lệ không khả dụng (Unavailable exceptions) là ngoại lệ duy nhất sẽ khiến việc ghi không thành công, vì vậy bất kỳ sự cố nào đều nghiêm trọng. Việc Cassandra không có khả năng đáp ứng các yêu cầu về tính nhất quán có thể có nghĩa là một số nút không hoạt động hoặc không thể truy cập được hoặc các cài đặt nhất quán nghiêm ngặt đang hạn chế tính khả dụng của cụm của bạn.