Trong phần này, chúng ta xem xét một số khía cạnh của kiến trúc của Cassandra để hiểu cách nó thực hiện công việc của mình. Chúng ta sẽ giải thích cấu trúc liên kết của một cụm (cluster) và cách các nút (nodes) tương tác trong thiết kế ngang hàng để duy trì trạng thái của cụm và trao đổi dữ liệu, bằng cách sử dụng các kỹ thuật như buôn chuyện (gossip), sửa chữa (repair), chuyển giao gợi ý (hinted handoff) và giao dịch nhẹ (lightweight transactions). Nhìn vào bên trong thiết kế của một nút, chúng ta kiểm tra các kỹ thuật kiến trúc mà Cassandra sử dụng để hỗ trợ đọc, ghi và xóa dữ liệu, đồng thời kiểm tra xem những lựa chọn này ảnh hưởng như thế nào đến các lựa chọn về kiến trúc như khả năng mở rộng, độ bền, tính khả dụng, khả năng quản lý và hơn thế nữa. Chúng ta cũng sẽ tìm hiểu về cấu trúc dữ liệu bên trong một nút, bao gồm nhật ký cam kết (commit logs), bảng ghi nhớ (memtables), bộ nhớ đệm (caches) và SSTables.
1. Data Centers và Racks
Cassandra thường được sử dụng trong các hệ thống có địa điểm riêng biệt về mặt vật lý trải dài. Cassandra cung cấp hai cấp độ nhóm được sử dụng để mô tả cấu trúc liên kết của một cụm: Data Centers và Racks. Một rack là một tập hợp logic của các nút trong khoảng cách gần nhau, có thể trên các máy vật lý trong một rack đơn lẻ của thiết bị. Một Data Center là một tập hợp logic của các rack, có thể nằm trong cùng một tòa nhà và được kết nối bằng mạng đáng tin cậy. Một cấu trúc liên kết mẫu với nhiều Data Centers và Racks được thể hiện trong Hình 1.
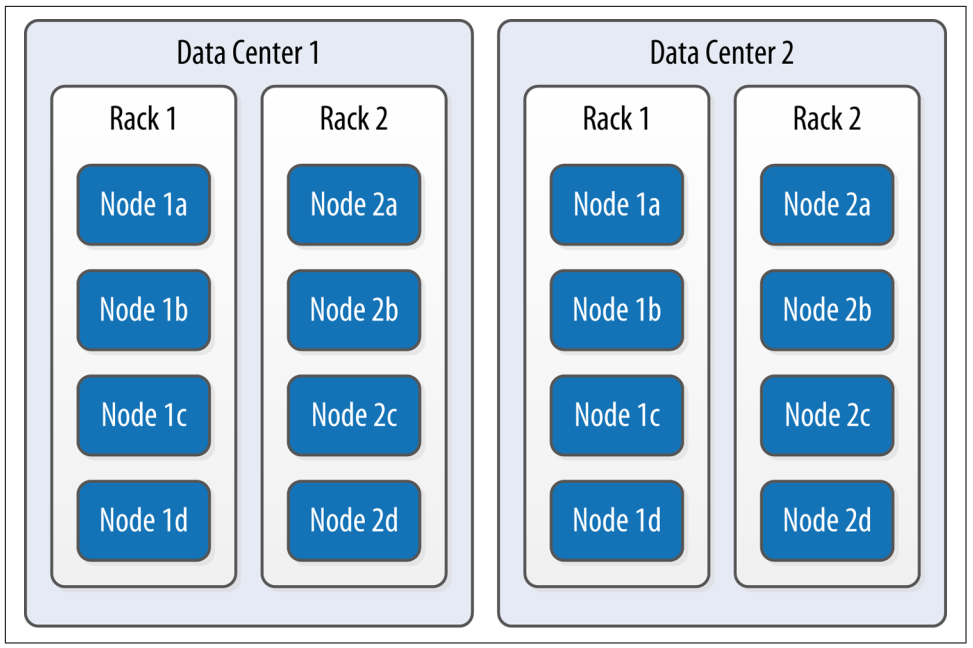
Ngoài ra, Cassandra đi kèm với một cấu hình mặc định đơn giản của một data center duy nhất (“datacenter1”) chứa một rack duy nhất (“rack1”).
Cassandra tận dụng thông tin bạn cung cấp về cấu trúc liên kết của cụm để xác định nơi lưu trữ dữ liệu và cách định tuyến các truy vấn một cách hiệu quả. Cassandra lưu trữ các bản sao dữ liệu của bạn trong các trung tâm dữ liệu mà bạn yêu cầu để tối đa hóa tính khả dụng và dung sai phân vùng, đồng thời ưu tiên định tuyến các truy vấn đến các nút trong data center cục bộ để tối đa hóa hiệu suất.
2. Buôn chuyện và phát hiện lỗi (Gossip and Failure Detection)
Để hỗ trợ khả năng phân quyền và phân vùng, Cassandra sử dụng giao thức gossip cho phép mỗi nút theo dõi thông tin trạng thái về các nút khác trong cụm. Gossiper chạy mỗi giây theo bộ đếm thời gian.
Các giao thức gossip (đôi khi được gọi là giao thức dịch) thường giả định một mạng bị lỗi, thường được sử dụng trong các hệ thống mạng rất lớn, phi tập trung và thường được sử dụng như một cơ chế tự động sao chép trong cơ sở dữ liệu phân tán. Họ lấy tên của chúng từ khái niệm chuyện phiếm của con người, một hình thức giao tiếp trong đó các đồng nghiệp có thể chọn người mà họ muốn trao đổi thông tin.
Nguồn gốc của giao thức Gossip
Thuật ngữ giao thức Gossip ban đầu được đặt ra vào năm 1987 bởi Alan Demers, một nhà nghiên cứu tại Trung tâm Nghiên cứu Xerox’s Palo Alto, người đang nghiên cứu các cách định tuyến thông tin qua các mạng không đáng tin cậy.
Giao thức gossip trong Cassandra chủ yếu được thực hiện bởi lớp org.apache.cassandra.gms.Gossiper, lớp này chịu trách nhiệm quản lý các gossip cho nút cục bộ. Khi một nút máy chủ được khởi động, nó tự đăng ký với gossiper để nhận thông tin trạng thái điểm cuối. Vì Cassandra gossip được sử dụng để phát hiện lỗi, lớp Gossiper duy trì một danh sách các nút còn sống và đã chết.
Đây là cách hoạt động của gossiper:
- Mỗi giây một lần, gossiper sẽ chọn một nút ngẫu nhiên trong cụm và bắt đầu khởi tạo một buổi nói chuyện phiếm với nó. Mỗi vòng nói chuyện phiếm cần ba tin nhắn.
- Người khởi xướng tin đồn gửi cho người bạn đã chọn của mình một tin nhắn GossipDigestSyn.
- Khi người bạn nhận được tin nhắn này, nó sẽ trả về một tin nhắn GossipDigestAck.
- Khi người khởi tạo nhận được tin nhắn ack từ người bạn, nó sẽ gửi cho người bạn đó một tin nhắn GossipDigestAck2 để hoàn thành vòng nói chuyện phiếm.
Khi gossiper xác định rằng một điểm cuối khác đã chết, nó sẽ “kết án (convicts)” điểm cuối đó bằng cách đánh dấu nó là đã chết trong danh sách cục bộ của nó và ghi lại thông tin đó.
Cassandra có hỗ trợ mạnh mẽ cho việc phát hiện lỗi, như được chỉ định bởi một thuật toán phổ biến cho máy tính phân tán có tên là Phi Accrual Failure Detector. Cách phát hiện lỗi này bắt nguồn từ Viện Khoa học và Công nghệ tiên tiến ở Nhật Bản vào năm 2004.
Phát hiện lỗi tích lũy dựa trên 2 ý tưởng chính. Ý tưởng chung đầu tiên là việc phát hiện lỗi phải linh hoạt, đạt được bằng cách tách nó khỏi ứng dụng đang được giám sát. Ý tưởng thứ hai và mới lạ hơn thách thức quan niệm về các thiết bị phát hiện thất bại truyền thống, được thực hiện bằng “nhịp tim (heartbeats)” đơn giản và quyết định xem một nút đã chết hay chưa chết dựa trên việc nhận được nhịp tim hay không. Nhưng việc phát hiện thất bại cộng dồn quyết định rằng cách tiếp cận này là ngây thơ và tìm thấy một vị trí ở giữa hai thái cực của sự sống và chết - một mức độ đáng ngờ.
Do đó, hệ thống giám sát sự cố tạo ra một mức độ “nghi ngờ (suspicion)” liên tục về mức độ tin cậy rằng một nút đã bị lỗi. Điều này là mong muốn vì nó có thể tính đến các biến động của môi trường mạng. Ví dụ: chỉ vì một kết nối bị bắt không có nghĩa là toàn bộ nút đã chết. Vì vậy, sự nghi ngờ cung cấp một dấu hiệu chủ động và linh hoạt hơn về khả năng thất bại yếu hơn hoặc mạnh hơn dựa trên diễn giải (lấy mẫu nhịp tim), trái ngược với đánh giá nhị phân đơn giản.
Phi Threshold and Accrual Failure Detectors
Bộ phát hiện lỗi tích lũy xuất ra một giá trị được liên kết với mỗi quá trình (hoặc nút) được gọi là Phi. Giá trị Phi thể hiện mức độ nghi ngờ rằng máy chủ có thể bị lỗi. Việc tính toán giá trị này được thiết kế để thích ứng khi đối mặt với các điều kiện mạng biến động, do đó, nó không phải là điều kiện nhị phân chỉ đơn giản là kiểm tra xem máy chủ đang hoạt động hay không.
Ngưỡng kết tội Phi trong cấu hình điều chỉnh độ nhạy của máy dò lỗi. Giá trị thấp hơn làm tăng độ nhạy và giá trị cao hơn làm giảm độ nhạy, nhưng không theo kiểu tuyến tính. Với cài đặt mặc định, Cassandra thường có thể phát hiện một nút bị lỗi trong khoảng 10 giây bằng cách sử dụng cơ chế này.
Phát hiện lỗi được triển khai trong Cassandra bởi lớp org.apache.cassandra.gms.FailureDetector, với lớp org.apache.cassandra.gms.IFailureDetector thực hiện giao diện. Chúng cùng nhau cho phép các hoạt động bao gồm:
- isAlive(InetAddressAndPort): Trình phát hiện sẽ báo cáo gì về tình trạng còn sống của một nút nhất định.
-
interpret(InetAddressAndPort): Được sử dụng bởi gossiper để giúp nó quyết định xem một nút còn sống hay không dựa trên mức độ nghi ngờ đạt được khi tính toán Phi.
- report(InetAddressAndPort): Khi một nút nhận được nhịp tim, nó sẽ gọi phương thức này.
3. Snitches
Công việc của snitch là cung cấp thông tin về cấu trúc liên kết mạng của bạn để Cassandra có thể định tuyến các yêu cầu một cách hiệu quả. Snitch sẽ tìm ra vị trí của các nút trong mối quan hệ với các nút khác. Snitch sẽ xác định độ gần máy chủ tương đối cho mỗi nút trong một cụm, được sử dụng để xác định các nút nào sẽ đọc và ghi từ đó.
Ví dụ: hãy kiểm tra cách snitch tham gia vào hoạt động đọc. Khi Cassandra thực hiện đọc, nó phải tiếp xúc với một số bản sao được xác định bởi mức độ nhất quán. Để hỗ trợ tốc độ đọc tối đa, Cassandra chọn một bản sao duy nhất để truy vấn đối tượng đầy đủ và yêu cầu bản sao bổ sung cho các giá trị băm để đảm bảo trả về phiên bản mới nhất của dữ liệu được yêu cầu. Snitch giúp xác định bản sao sẽ trả về nhanh nhất và đây là bản sao được truy vấn để tìm toàn bộ dữ liệu.
Snitch mặc định (SimpleSnitch) là cấu trúc liên kết không biết; nghĩa là nó không biết về các rack và data center trong một cụm, điều này làm cho nó không phù hợp cho việc triển khai nhiều data center. Vì lý do này, Cassandra đi kèm với một số nút cho các cấu trúc liên kết mạng và môi trường đám mây khác nhau, bao gồm Amazon EC2, Google Cloud và Apache Cloudstack.
Các snitche có thể được tìm thấy trong gói org.apache.cassandra.locator. Mỗi snitch triển khai giao diện IEndpointSnitch.
Mặc dù Cassandra cung cấp một cách có thể cắm để mô tả tĩnh cấu trúc liên kết cụm của bạn, nó cũng cung cấp một tính năng gọi là tính năng snitching động (dynamic snitching) giúp tối ưu hóa việc định tuyến đọc và ghi theo thời gian. Đây là cách nó hoạt động. Snitch của bạn đã chọn được bọc bằng một snitch khác gọi là DynamicEndpointSnitch. Snitch động có được sự hiểu biết cơ bản về cấu trúc liên kết từ snitch đã chọn. Sau đó, nó giám sát hiệu suất của các yêu cầu đến các nút khác, thậm chí theo dõi những thứ như nút nào đang thực hiện nén. Dữ liệu hiệu suất được sử dụng để chọn bản sao tốt nhất cho mỗi truy vấn. Điều này cho phép Cassandra tránh các yêu cầu định tuyến đến các bản sao đang bận hoặc hoạt động kém.
Việc triển khai tính năng động sử dụng phiên bản sửa đổi của cơ chế phát hiện lỗi Phi được sử dụng bởi gossip. Ngưỡng mức độ kém (badness threshold) là một tham số có thể cấu hình xác định mức độ kém hơn mà nút ưu tiên phải thực hiện so với nút hoạt động tốt nhất để mất trạng thái ưu tiên của nó. Điểm số của mỗi nút được đặt lại định kỳ để cho phép một nút hoạt động kém chứng minh rằng nó đã khôi phục và lấy lại trạng thái ưa thích của nó.
4. Tài liệu tham khảo
- Ebook Cassandra: The Definitive Guide by Jeff Carpenter and Eben Hewitt