Rings and Tokens
Cassandra đại diện cho dữ liệu được quản lý bởi một cụm dưới dạng một vòng (ring). Mỗi nút trong vòng được gán một hoặc nhiều dải dữ liệu được mô tả bằng mã riêng (token), xác định vị trí của nó trong vòng. Ví dụ: trong cấu hình mặc định, token là ID số nguyên 64 bit được sử dụng để xác định từng phân vùng. Điều này cung cấp một phạm vi của token từ −2^63 đến 2^63 − 1.
Một nút yêu cầu quyền sở hữu phạm vi giá trị nhỏ hơn hoặc bằng mỗi mã token và lớn hơn mã token cuối cùng của nút trước đó, được gọi là phạm vi mã token. Nút có mã token thấp nhất sở hữu phạm vi nhỏ hơn hoặc bằng mã token của nó và phạm vi lớn hơn mã token cao nhất, còn được gọi là phạm vi gói (wrapping range). Trong này theo cách, các thẻ chỉ định một vòng hoàn chỉnh. Bằng cách này, các token chỉ định một vòng hoàn chỉnh. Hình 1 cho thấy một lý thuyết bố cục vòng bao gồm các nút trong một data center duy nhất. Sự sắp xếp cụ thể này được cấu trúc để phạm vi mã token liên tiếp được trải rộng trên các nút trong các rack khác nhau.
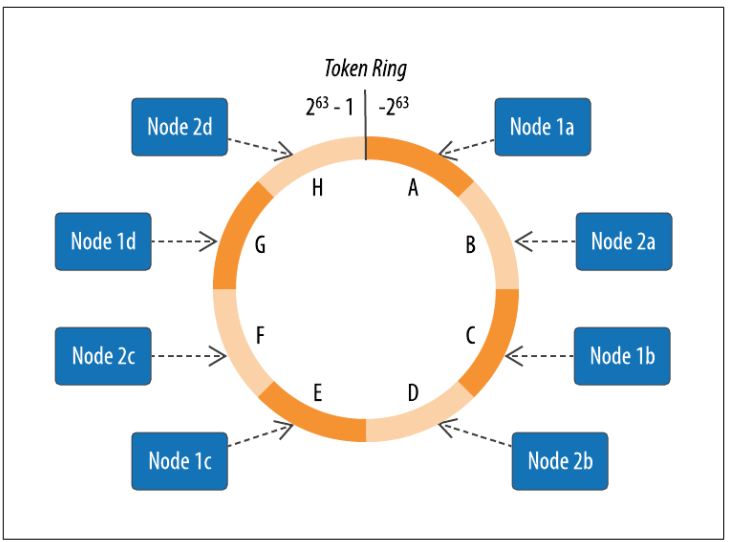
Dữ liệu được gán cho các nút bằng cách sử dụng hàm băm để tính mã token cho khóa phân vùng. Mã khóa token phân vùng này được so sánh với các giá trị mã token cho các nút khác nhau để xác định phạm vi và do đó nút sở hữu dữ liệu. Phạm vi mã token được đại diện bởi lớp org.apache.cassandra.dht.Range.
Để xem ví dụ về mã token đang hoạt động, hãy truy cập bảng user trong phần sau. Ngôn ngữ CQL cung cấp hàm token() mà chúng ta có thể sử dụng để yêu cầu giá trị của mã token tương ứng với khóa phân vùng, trong trường hợp này là last_name:
cqlsh:my_keyspace> SELECT last_name, first_name, token(last_name) FROM user;
last_name | first_name | system.token(last_name)
----------+------------+-------------------------
Rodriguez | Mary | -7199267019458681669
Scott | Isaiah | 1807799317863611380
Nguyen | Bill | 6000710198366804598
Nguyen | Wanda | 6000710198366804598
(5 rows)
Như bạn có thể mong đợi, chúng ta thấy một mã token khác nhau cho mỗi phân vùng và cùng một mã token xuất hiện cho hai hàng được biểu thị bằng giá trị khóa phân vùng “Nguyen”.
Virtual Nodes
Các phiên bản đầu tiên của Cassandra đã gán một mã token duy nhất (và do đó ám chỉ một dải mã token duy nhất) cho mỗi nút, theo cách khá tĩnh, yêu cầu bạn phải tính toán các mã token cho mỗi nút. Mặc dù có sẵn các công cụ để tính toán mã token dựa trên một số nút nhất định, đó vẫn là một quy trình thủ công để định cấu hình thuộc tính initial_token cho mỗi nút trong tệp cassandra.yaml. Điều này cũng làm cho việc thêm hoặc thay thế một nút trở thành một hoạt động tốn kém, vì việc tái cân bằng cụm đòi hỏi phải di chuyển nhiều dữ liệu.
Bản phát hành 1.2 của Cassandra đã giới thiệu khái niệm về các nút ảo, còn được gọi tắt là vnodes. Thay vì chỉ định một mã token cho một nút, phạm vi mã token được chia thành nhiều phạm vi nhỏ hơn. Mỗi nút vật lý sau đó được gán nhiều mã token. Về mặt lịch sử, mỗi nút đã được gán 256 trong số các mã token này, có nghĩa là nó đại diện cho 256 nút ảo (mặc dù chúng ta sẽ thảo luận về những thay đổi có thể có đối với giá trị này trong phần sau). Các nút ảo đã được bật theo mặc định kể từ phiên bản 2.0.
Vnodes giúp dễ dàng duy trì một cụm chứa các máy không đồng nhất. Đối với các nút trong cụm của bạn có sẵn nhiều tài nguyên máy tính hơn, bạn có thể tăng số lượng vnode bằng cách đặt thuộc tính num_tokens trong tệp cassandra.yaml. Ngược lại, bạn có thể đặt num_tokens thấp hơn để giảm số lượng vnodes cho các máy có khả năng thấp hơn.
Cassandra tự động xử lý việc tính toán phạm vi mã token cho mỗi nút trong cụm tương ứng với giá trị số mã token của chúng. Việc gán mã token cho vnodes được tính toán bởi lớp org.apache.cassandra.dht.tokenallocator.ReplicationAware TokenAllocator.
Một lợi thế nữa của các nút ảo là chúng tăng tốc một số hoạt động Cassandra nặng hơn như khởi động một nút mới, ngừng hoạt động một nút và sửa chữa một nút. Điều này là do tải liên quan đến các hoạt động trên nhiều phạm vi nhỏ hơn được trải đều hơn trên các nút trong cụm.
Partitioners (Phân vùng)
Trình phân vùng xác định cách dữ liệu được phân phối qua các nút trong cụm. Như đã đề cập ở phần trước, Cassandra tổ chức các hàng trong các phân vùng. Mỗi hàng có một khóa phân vùng được sử dụng để xác định phân vùng mà nó thuộc về. Do đó, trình phân vùng là một hàm băm để tính toán mã token của khóa phân vùng. Mỗi hàng dữ liệu được phân phối trong vòng theo giá trị của mã khóa phân vùng token. Như trong Hình 2, vai trò của trình phân vùng là tính toán mã token dựa trên các cột khóa phân vùng. Bất kỳ cột phân cụm nào có thể có trong khóa chính được sử dụng để xác định thứ tự của các hàng trong một nút nhất định sở hữu mã token đại diện cho phân vùng đó.
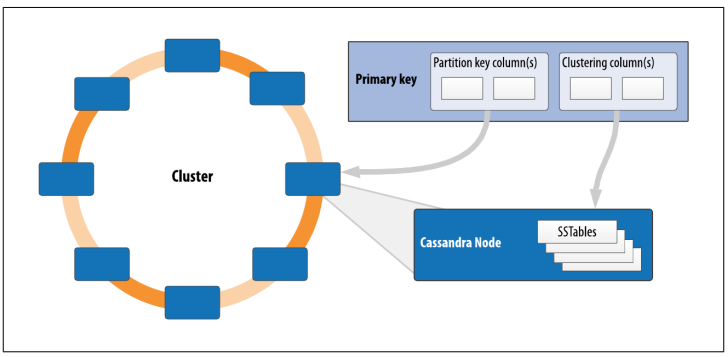
Cassandra cung cấp một số phân vùng khác nhau trong gói org.apache.cassandra.dht (DHT là viết tắt của distributed hash table - bảng băm phân tán). Murmur3Partitioner đã được thêm vào trong phiên bản 1.2 và là trình phân vùng mặc định kể từ đó; nó là một thực hiện Java hiệu quả trên các thuật toán thì thầm (murmur) phát triển bởi Austin Appleby. Nó tạo ra các mã băm 64-bit. Mặc định trước đó là RandomPartitioner.
Do thiết kế thường có thể cắm được của Cassandra, bạn cũng có thể tạo trình phân vùng của riêng mình bằng cách triển khai lớp org.apache.cassandra.dht.IPartitioner và đặt nó trên đường dẫn phân vùng của Cassandra. Tuy nhiên, lưu ý rằng trình phân vùng mặc định không thường xuyên được thay đổi trong thực tế và bạn không thể thay đổi trình phân vùng sau khi khởi tạo một cụm.
Chiến lược nhân rộng (Replication Strategies)
Một nút đóng vai trò là một bản sao cho các phạm vi dữ liệu khác nhau. Nếu một nút gặp trục trặc, các bản sao khác có thể phản hồi các truy vấn cho phạm vi dữ liệu đó. Cassandra sao chép dữ liệu qua các nút theo cách minh bạch đối với người dùng và yếu tố sao chép là số lượng nút trong cụm của bạn sẽ nhận được các bản sao (replicas) của cùng một dữ liệu. Nếu hệ số sao chép của bạn là 3, thì ba nút trong vòng sẽ có các bản sao của mỗi hàng.
Bản sao đầu tiên sẽ luôn là nút xác nhận phạm vi mà mã token rơi vào, nhưng phần còn lại của các bản sao được đặt theo chiến lược sao chép - replication strategy (đôi khi còn được gọi là chiến lược đặt bản sao - replica placement strategy).
Để xác định vị trí bản sao, Cassandra triển khai mô hình chiến lược Gang of Four, được phác thảo trong lớp trừu tượng chung org.apache.cassandra.locator.AbstractReplicationStrategy, cho phép triển khai các thuật toán khác nhau (các chiến lược khác nhau để hoàn thành cùng một công việc). Mỗi thuật toán triển khai được đóng gói bên trong một lớp mở rộng duy nhất AbstractReplicationStrategy.
Ngoài ra, Cassandra cung cấp hai cách triển khai chính của giao diện này (phần mở rộng của lớp trừu tượng): SimpleStrategy và NetworkTopologyStrategy. SimpleStrategy đặt các bản sao tại các nút liên tiếp xung quanh vòng, bắt đầu với nút được chỉ ra bởi trình phân vùng. NetworkTopologyStrategy cho phép bạn chỉ định một hệ số nhân bản khác nhau cho mỗi data center. Trong một data center, nó phân bổ các bản sao đến các rack khác nhau để tối đa hóa tính khả dụng. NetworkTopologyStrategy được sử dụng cho các keyspaces trong triển khai thực tế, ngay cả những keyspaces ban đầu được tạo với một data center duy nhất, vì việc thêm một data center bổ sung sẽ đơn giản hơn nếu có nhu cầu.
Chiến lược sao chép kế thừa (Legacy Replication Strategies)
Chiến lược thứ ba, OldNetworkTopologyStrategy được cung cấp để tương thích ngược. Trước đây nó được gọi là RackAwareStrategy, trong khi SimpleStrategy trước đây được gọi là RackUnawareStrategy. NetworkTopologyStrategy trước đây được gọi là DataCenterShardStrategy. Những thay đổi này đã có hiệu lực trong bản phát hành 0.7.
Chiến lược được đặt độc lập cho mỗi keyspaces và là một tùy chọn bắt buộc để tạo một keyspaces.
Tài liệu tham khảo
- Ebook Cassandra: The Definitive Guide by Jeff Carpenter and Eben Hewitt